表題のことについて検証してみましょう。
目次
前提
本題に入る前に、Webフォントを配信する際の前提について説明します。分かっている方は読み飛ばしてもらって大丈夫です。
Webページ上で独自のフォントを読み込むには
CSSの font-family 属性に使いたいフォント名を書くことで、Webページ上のコンテンツのフォントを変えることができます。
昔は、あらゆるシステムにインストールされていることが想定されているフォント*1を使うぐらいしかできませんでしたが、最近ではCSSに独自のフォントを読み込むための仕組みが用意されています。
より詳しくは ウェブフォント - ウェブ開発を学ぶ | MDN を読んでください。
フォントファイルのサイズ
一般に、フォントに含まれる文字数とフォントファイルのサイズは比例します。英数字・記号ぐらいならまだよいのですが、ラテン文字・キリル文字・ひらがな・カタカナ・漢字……と文字を含めていくとどんどん大きなフォントファイルになります。
参考までに、2022/3/24 時点のNoto Sansフォント (TrueType形式) は340KBですが、Noto Sans CJKのJPフォント (同じくTrueType形式) は34MBもあります*2。
ページを閲覧したら34MBのファイルをダウンロードすることになる、と考えると迫力がありますね。実際にはフォントファイルを強くキャッシュすることができるはずですが、転送量はできるだけ抑えられると、ユーザー体験にも運用コスト面にも優しくなります。
フォントファイルのサイズを抑える工夫
何もフォントを読み込まない、ということになるとデザインに大きく制約がかかることになります。とはいえあまり大きなフォントファイルを配信するとユーザー体験が悪くなるので、なんとかしてファイルサイズを抑えることを考えます。
フォントファイルのサイズを抑える方針として、大きく以下の2つがあります。これらを組み合わせることで、転送量を抑えつつリッチなデザインのWebページを作ることができます。
- フォントファイルを分割し、必要に応じて読み込む
- フォントファイルを圧縮する
それぞれ簡単に説明します。
フォントファイルを分割し、必要に応じて読み込む
フォントファイルから必要なグリフ (文字) のデータだけを抽出する処理をサブセット化といいます。文字種ごとにサブセット化を繰り返すことで、フォントファイルを分割できます。サブセット化は、fontToolsのpyftsubsetコマンドや各種ソフトウェアによって実現できます。
分割したフォントファイルを必要に応じて読み込むには、CSSの @font-family ルールを使います。以下は、Google Fontsが配信しているUbuntuフォントにおける記述例です。
/* 前略 */ /* latin-ext */ @font-face { font-family: 'Ubuntu'; font-style: normal; font-weight: 400; src: url(https://fonts.gstatic.com/s/ubuntu/v19/4iCs6KVjbNBYlgoKcQ72nU6AF7xm.woff2) format('woff2'); unicode-range: U+0100-024F, U+0259, U+1E00-1EFF, U+2020, U+20A0-20AB, U+20AD-20CF, U+2113, U+2C60-2C7F, U+A720-A7FF; } /* latin */ @font-face { font-family: 'Ubuntu'; font-style: normal; font-weight: 400; src: url(https://fonts.gstatic.com/s/ubuntu/v19/4iCs6KVjbNBYlgoKfw72nU6AFw.woff2) format('woff2'); unicode-range: U+0000-00FF, U+0131, U+0152-0153, U+02BB-02BC, U+02C6, U+02DA, U+02DC, U+2000-206F, U+2074, U+20AC, U+2122, U+2191, U+2193, U+2212, U+2215, U+FEFF, U+FFFD; }
Ubuntuという名前のfont-familyで、複数の @font-face ルールを記述しています。文字種ごとに読み込むべきフォントファイルを定義しています。このとき、どの文字種 (Unicodeのコードポイントの範囲) に対して有効なフォントなのかを宣言するために unicode-range 記述子を使っています。
フォントファイルを圧縮する
フォントファイルを分割することでファイルサイズを抑えることができますが、さらに圧縮をかけるともっと小さくすることができます。フォントファイルを圧縮する際のフォーマットとしては、WOFFやWOFF2があります。フォントファイルの圧縮もfontToolsのpyftsubsetコマンドで実現できます。
手元でNoto Sansフォント (TrueType形式) を圧縮すると、それぞれ以下のサイズになりました。WOFFではファイルサイズが半分近く、WOFF2ではそれ以下に削減されています。
| フォント | 圧縮前 | WOFF | WOFF2 |
|---|---|---|---|
| Noto Sans Regular | 340KB | 177KB | 120KB |
| Noto Sans CJK jp Regular | 34MB | 19MB | 14MB |
前提おわり
ここまで前提でした。リッチなユーザー体験とコスト削減を両立するために、Webフォントを配信する際に気をつける点がいくつかあることを分かっていただけたかと思います。
本題
ここから本題に入ります。Webフォントを読み込む際に unicode-range を指定しなかったらどうなるのでしょうか?
規格によると
CSS Fonts Module Level 4のWorking Draftを読み解いて、どうなるのか確認しましょう。といっても今回読むべき箇所は多くありません。
4.5. Character range: the unicode-range descriptor
unicode-range 修飾子についての説明が書いてあります。この節の先頭の表を読むと、unicode-range の初期値が U+0-10FFFF であることが分かります。つまり、unicode-range を指定しなかった場合、あらゆる文字をサポートするフォントであるとみなされます。
4.5.1. Using character ranges to define composite fonts
複数のフォントを組み合わせる際の挙動について書いてあります。今回気にしたいのは第2段落の記述です。
If the unicode ranges overlap for a set of @font-face rules with the same family and style descriptor values, the rules are ordered in the reverse order they were defined; the last rule defined is the first to be checked for a given character.
つまり、同じfont-familyかつスタイルの @font-face ルールが複数定義されていて、かつ unicode-range に指定されたコードポイントの範囲が重複している場合、最後に定義された @font-face のフォントから順に試行されてフォールバックすることが規定されています。
実験する
ここまで規格で確認してきた挙動を実験して確かめてみましょう*3。
準備
以下のリポジトリを用意しました。
with-unicode-range.css、without-unicode-range.cssのどちらでもUbuntuフォントを読み込んでいます。また、各HTMLの本文にはキリル文字だけを書いています。with-unicode-range.htmlからはwith-unicode-range.cssを、without-unicode-range.htmlからはwithout-unicode-range.cssをそれぞれ読み込んでいます。
with-unicode-range.cssでは、Ubuntuフォントに対応する @font-face を、先頭から以下の文字種の順に定義しています。視認性を上げるために、各フォントファイルのURLの末尾に文字種をクエリパラメータで入れています。
- 拡張キリル文字 (cyrillic-ext)
- キリル文字 (cyrillic)
- 拡張ギリシャ文字 (greek-ext)
- ギリシャ文字 (greek)
- 拡張ラテン文字 (latin-ext)
- ラテン文字 (latin)
without-unicode-range.cssでは、with-unicode-range.cssの記述から unicode-range を消して、更に拡張キリル文字とキリル文字の定義順を入れ替えてあります。
実験方法
with-unicode-range.html, without-unicode-range.html をそれぞれハード再読み込みします。その際にフォントがどのように読み込まれるのか、ブラウザの開発者ツールで確認します。
実験結果
Chromeの開発者ツールのNetworkタブから、フォントファイル (Fonts) だけに絞り込んだ結果が以下です。
| html | Networkタブ |
|---|---|
| with-unicode-range.html | 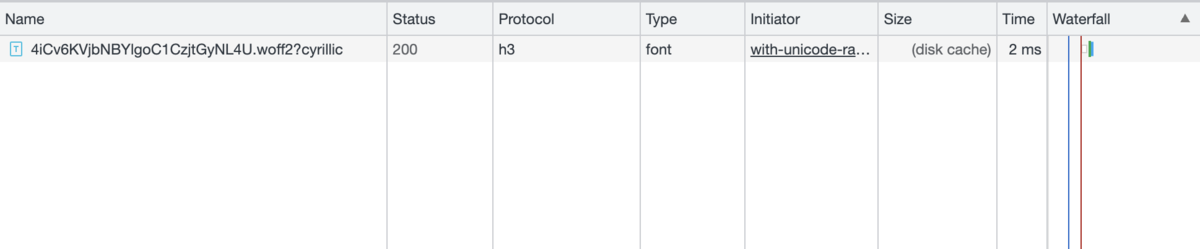 |
| without-unicode-range.html | 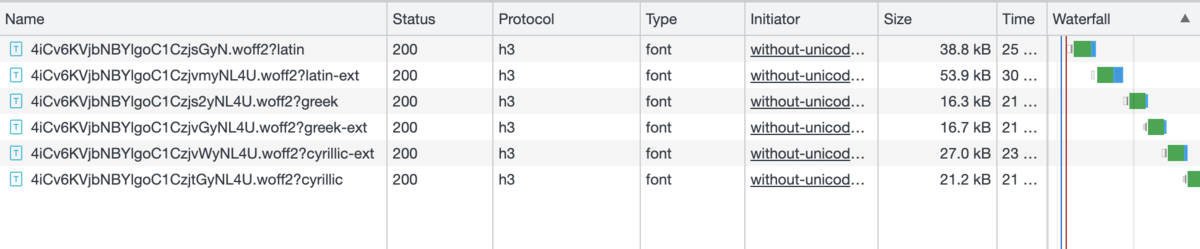 |
with-unicode-range.htmlではフォントファイル分割の狙いどおりキリル文字のフォントだけが読み込まれています。一方で、without-unicode-range.htmlではラテン文字から順にフォントが読み込まれて、最後にキリル文字のフォントが読み込まれました。
まとめ
Webフォントを分割して読み込む際に unicode-range を指定しなかった場合の挙動については規格で規定されていました。ユーザー体験を向上し、転送量を抑えるためにも @font-face の定義は適切に記述したいですね。
*1:ウェブセーフフォントという。ArialやCourier Newなどが該当するらしい
*2:それぞれGitHubからmainブランチのTTFファイルをダウンロードして確認
*3:実験して挙動を確かめてから規格を読みに行ったので、自分がとった流れとは逆