これはKMC Advent Calendar 2021 - Adventar 2日目の記事です。
あらすじ
List::Utilの pairs 関数をPythonでも使いたくなって、itertoolsの関数を組み合わせて再現できないかと思ったけど、その時点ではうまくできなかった。仕方ないので手作りする。
ちなみに後述の通り、itertoolsの関数で再現する方法があるし、要件によっては組み込み関数だけで再現できる。
List::Utilの pairs 関数について
リスト @xs を受け取り、([$xs[0], $xs[1]], [$xs[2], $xs[3]], ...) のように、要素を2個ずつに区切った配列リファレンス*1のリストを返す。
% perl -MData::Dumper -MList::Util -e 'print Dumper([List::Util::pairs (qw(foo bar baz qux)) ])'
$VAR1 = [
bless( [
'foo',
'bar'
], 'List::Util::_Pair' ),
bless( [
'baz',
'qux'
], 'List::Util::_Pair' )
];
奇数長のリストの場合は、最後のペアの2番目の要素が undef になる。
% perl -MData::Dumper -MList::Util -e 'print Dumper([List::Util::pairs (qw(foo bar baz)) ])'
$VAR1 = [
bless( [
'foo',
'bar'
], 'List::Util::_Pair' ),
bless( [
'baz',
undef
], 'List::Util::_Pair' )
];
ちなみにRubyでは
Rubyでは Enumberable モジュールに each_slice というメソッドが生えていて、引数2のとき pairs 関数に近い挙動になる。ただし不足値を nil で補うようなことはしない。
% ruby -e 'p %w(foo bar baz qux).each_slice(2).to_a' [["foo", "bar"], ["baz", "qux"]]
作ってみる
Pythonだとペアを返すときはタプルを使うことが多そうなので、そのようにしてみる。要件としては以下の通り。
Pythonのリスト xs を受け取り、(xs[0], xs[1]), (xs[2], xs[3]) のようなタプルを順にyieldするジェネレータを作る。
奇数長のときの挙動はいったん無視する (つまり、再現されてもされなくてもよい)。リストの末尾に None を足せばよいだけなので、必要に応じて None を補完するのは難しくないはず。
一般化するなら、引数として任意のイテレータを取れるとかっこいいけど、そこまでは考えずとりあえずリストのことだけを考える。
2要素ずつリストに溜める (pairs_append_yield)
素朴には、2要素ずつ一時的なリストに溜めてからタプルに変換する方法が考えられる。以下のようなコードで実現できる。
def pairs_append_yield(xs): buf = [] for x in xs: buf.append(x) if len(buf) >= 2: yield tuple(buf) buf.clear()
2要素ずつインデックスアクセスする (pairs_index_access)
以下のように、インデックスをちゃんと計算することで短く記述できる。
def pairs_index_access(xs): for i in range(len(xs) // 2): yield xs[2 * i], xs[2 * i + 1]
リストの先頭2要素ずつ取って書き換える (pairs_slice_copy)
リストの先頭2要素をタプルにしてyieldして、残りのリストをスライスしたもので書き換える方法もありますね、と教えてもらった。
def pairs_slice_copy(xs): for _ in range(len(xs) // 2): yield tuple(xs[:2]) xs = xs[2:]
偶奇に着目する (pairs_even_odd)
偶奇に着目すれば実現できないか、と一番最初に思いついたのがこの実装。書いた当時は map と filter を組み合わせていたけどさすがに内包表記の方が読みやすいという意見をもらって書き換えた。その通りだと思う。
def pairs_even_odd(xs): evens = (x for i, x in enumerate(xs) if i % 2 == 0) odds = (x for i, x in enumerate(xs) if i % 2 == 1) for even, odd in zip(evens, odds): yield even, odd
(x for x in ...) のように括弧で囲んだものはジェネレータ式なので、リスト内包表記と違って要素が即座に評価されるわけではない。そういえば以前にリスト内包表記の記事を書いていた。
計測する
いろいろな方法で実現できるけど、実行速度が気になる。ということで計測する。
計測方法
以下のようなスクリプト*2を用意して、 M の値を適当に変えてベンチマークを行う*3。ジェネレータを生成するだけだと何も評価されずに一瞬で終わるので、最後にリストに変換することでベンチマークとしている。
def benchmark(M): N = 10000 target_functions = [ 'pairs_append_yield', 'pairs_index_access', 'pairs_slice_copy', 'pairs_even_odd', ] for funcname in target_functions: stmt = f'xs = list(range({M})); list({funcname}(xs))' elapsed = timeit.timeit(stmt, number=N, globals=globals()) print(f'{funcname}\t{elapsed}') if __name__ == '__main__': M = int(sys.argv[1]) benchmark(M)
結果
M = 100 pairs_append_yield 0.15541480000001684 pairs_index_access 0.06048979999968651 pairs_slice_copy 0.15620510000007926 pairs_even_odd 0.16310169999997015 M = 1000 pairs_append_yield 1.3216025000001537 pairs_index_access 0.6861401999999543 pairs_slice_copy 5.359008399999766 pairs_even_odd 1.6237092000001212 M = 2000 pairs_append_yield 2.619715900000301 pairs_index_access 1.4473646000001281 pairs_slice_copy 21.03976220000004 pairs_even_odd 3.3101166000001285 M = 5000 pairs_append_yield 6.534201899999971 pairs_index_access 3.7242138000001432 pairs_slice_copy 137.1054666 pairs_even_odd 8.382808699999714
グラフにすると以下のような感じ。
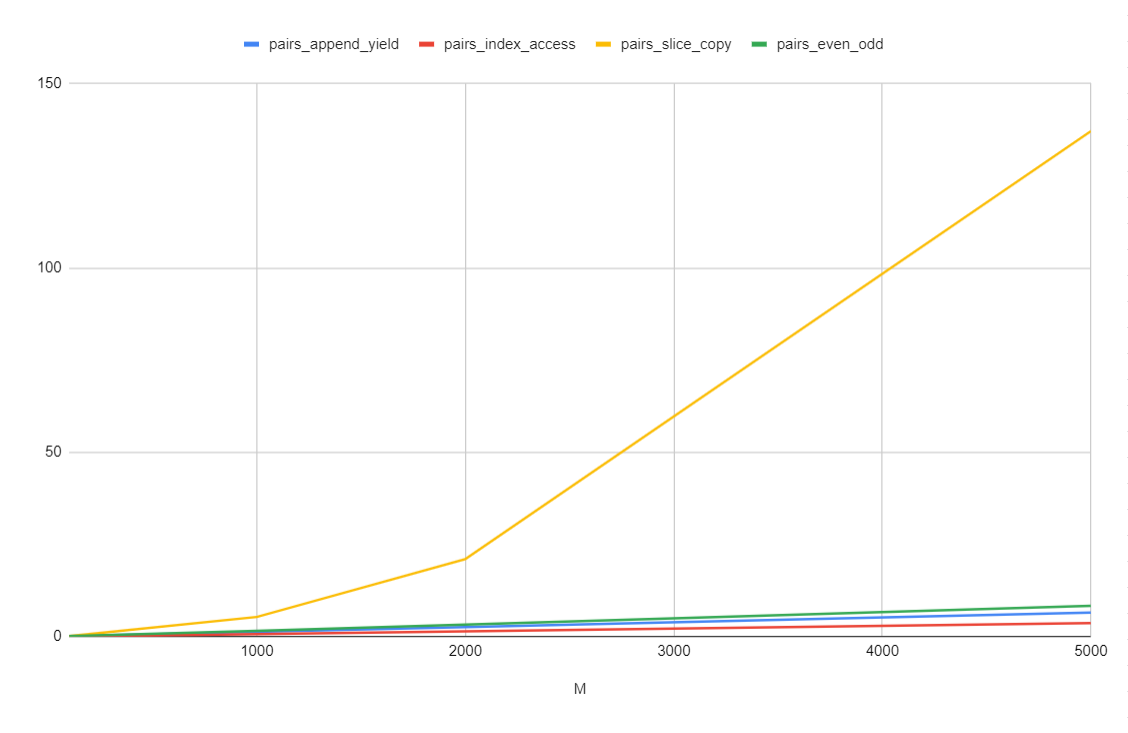
考察
分かったこと
M が小さいうちは大差ないけど、大きくなるにつれて差が有意に出てきた。とくに pairs_slice_copy がかなり重たく、pairs_index_access が一番速い。
重さ
どの方法も、リストの要素数に比例するforループが1つあるので、少なくともO(N)ぐらいの計算量であることは間違いなさそう。
pairs_slice_copy では、元のリストをスライスしたリストで書き換えている。このときにスライスのコピーが発生している分のコストがかかっていることが予想できる。
pairs_even_odd は中間のジェネレータを生成したり、偶奇で条件分岐したりする分のコストがかかっていそう。
pairs_append_yield はリストに要素を追加したりリストをクリアしたりするコストがかかっていそうだけど、上の2つに比べると微々たるものではありそう?
ということで、余分なオブジェクトを作ったり加工したりする必要がないぶん、pairs_index_access がいちばん速かった、ということになる。
ちなみに、itertoolsを使う方法
Stackoverflowにあると教えてもらった。更によく見るとitertoolsのドキュメント内に grouper という名前で登場していた……。
今回の要件では足りない値を None でfillする必要はないので、少し修正するとこんな感じになるであろう。
def pairs_grouper(xs): args = [iter(xs)] * 2 return zip(*args)
よく見ると、同じイテレータを浅くコピーしている。これによってイテレータの要素をずらして所望の挙動を得ている。賢い……。
計測する
速度が気になるのでベンチマークを取ってみる。ここまで最速だった pairs_index_access と比べてどれくらい変わるのだろうか?
def benchmark(M): N = 10000 target_functions = [ 'pairs_index_access', 'pairs_grouper', ] for funcname in target_functions: stmt = f'xs = list(range({M})); list({funcname}(xs))' elapsed = timeit.timeit(stmt, number=N, globals=globals()) print(f'{funcname}\t{elapsed}')
結果
% for m in 100 1000 2000 5000 10000; do echo M = $m; python3 pairs.py $m; done M = 100 pairs_index_access 0.0634912000004988 pairs_grouper 0.023701099999925646 M = 1000 pairs_index_access 0.7986147999999957 pairs_grouper 0.2131203999997524 M = 2000 pairs_index_access 1.4482410000000527 pairs_grouper 0.46308439999938855 M = 5000 pairs_index_access 3.6113817999994353 pairs_grouper 1.1623411999999007 M = 10000 pairs_index_access 7.749021399999947 pairs_grouper 2.4021535000001677
pairs_grouper の方が、pairs_index_access に比べて3倍ぐらい高速だった。予想では pairs_index_access より少し遅くなると思っていたので意外だった。こんなに速い理由は誰か知ってたら教えてください。
どうですか
言語によっては組み込みライブラリにこういう実装があるのかもしれない。効率的な実装について考えるいい機会にもなった。イテレータ・ジェネレータを使い倒すと高速かつ最小手数で実現できる場合がある。
あと、難しく考えすぎない、肩の力を抜くのも大事だと改めて認識した。深夜テンションで書いたコードは、寝て起きてから再検討するぐらいがちょうどよさそう。
C拡張を書いたら速度を上げられるかもしれないけど、そこまでやることもなさそう。
KMCM
KMC (京大マイコンクラブ) では、効率的な実装について考えるのが好きな部員を募集しています。KMCに入部制限はありません。どなたでも入部できます。オンラインでも活動しています。
競技プログラミングの勉強会もやっています。
次回予告
明日はたまろんさんで Rustコンパイラのソースコードリーディング - tamaron's diary です。
*1:厳密にはblessされたオブジェクトだけど、この記事では触れない
*2:完全なスクリプトは https://github.com/utgwkk/20211127-sketch-each-cons-python/blob/main/pairs.py にある
*3:測定環境: Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz, 32GB RAM, Ubuntu 20.04 on WSL
























