tl;dr
pdftotext を使えばできる- じぶんのスライドのbounding boxに着目すればだいたいうまくいく
動機
pdftotext は,PDFファイルからテキストの情報を抜き出すことができるコマンドである.
これは単にテキストを抽出するだけでなく, -bbox-layout オプションを渡すことでbounding boxの詳細な情報も含めてXMLとして吐いてくれるのである.
このXMLをうまく使えばPDFファイルから発表タイトルを抜き出せるのではなかろうか.
今回は自分のスライドについて考えることにした.
考察
たとえば,このスライドを pdftotext にかけた結果は次のようになる.
 gyazo.com
gyazo.com
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>2018shinkan-pub</title>
<meta name="Creator" content="Keynote"/>
<meta name="Producer" content="Mac OS X 10.13.4 Quartz PDFContext"/>
<meta name="CreationDate" content=""/>
</head>
<body>
<doc>
<page width="1024.000000" height="768.000000">
<flow>
<block xMin="38.000000" yMin="76.200000" xMax="986.978000" yMax="496.200000">
<line xMin="38.000000" yMin="76.200000" xMax="338.000000" yMax="136.200000">
<word xMin="38.000000" yMin="76.200000" xMax="338.000000" yMax="136.200000">みなさん,</word>
</line>
<line xMin="38.000000" yMin="166.200000" xMax="815.000000" yMax="226.200000">
<word xMin="38.000000" yMin="166.200000" xMax="815.000000" yMax="226.200000">キーワード検索してますか?</word>
</line>
<line xMin="38.000000" yMin="256.200000" xMax="450.200000" yMax="316.200000">
<word xMin="38.000000" yMin="256.200000" xMax="450.200000" yMax="316.200000">してますよね?</word>
</line>
<line xMin="38.000000" yMin="346.200000" xMax="935.600000" yMax="406.200000">
<word xMin="38.000000" yMin="346.200000" xMax="935.600000" yMax="406.200000">それでは高速なキーワード検索を</word>
</line>
<line xMin="38.000000" yMin="436.200000" xMax="986.978000" yMax="496.200000">
<word xMin="38.000000" yMin="436.200000" xMax="986.978000" yMax="496.200000">支える技術についてお話しします.</word>
</line>
</block>
<block xMin="135.000000" yMin="577.800000" xMax="889.080000" yMax="617.800000">
<line xMin="135.000000" yMin="577.800000" xMax="889.080000" yMax="617.800000">
<word xMin="135.000000" yMin="577.800000" xMax="404.440000" yMax="617.800000">2018/04/16</word>
<word xMin="417.760000" yMin="577.800000" xMax="680.160000" yMax="617.800000">KMC例会講座</word>
<word xMin="693.480000" yMin="577.800000" xMax="889.080000" yMax="617.800000">@utgwkk</word>
</line>
</block>
</flow>
</page>
</doc>
</body>
</html>
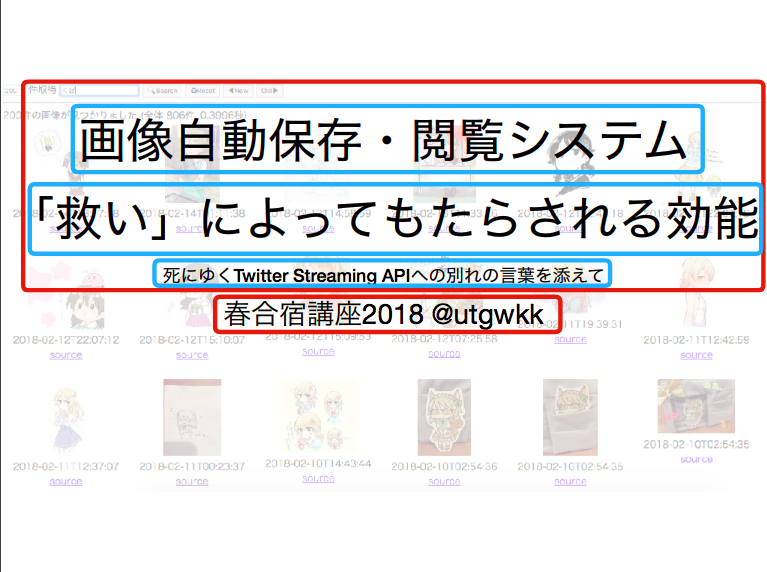
これを図示するとこうなる.以下,枠線について,赤は <flow> ,青は <block>, 黄色は <line>, 緑色は <word> とする*1.
 gyazo.com
gyazo.com
この場合については,
- 最初の
<block> をとる
- 各
<line> 内の全ての <word> のtextContentを結合する
- それらを結合する
といった手順を踏めばタイトルが復元できそうである.
最近の私のスライドは大体こちらの方式が適用できた.
ざっと見た感触だと,めちゃくちゃに凝ったタイトルスライドを作るなどしなければこちらの方法でいけるのではなかろうかと思う.
実装
pdftotext のPythonバインディングを見つける前にsubprocessでゴリッとやってしまった.
XMLを読み取るのがなかなか難しいし,可読性のためにもxml.etree.ElementTreeよりももうちょっといいものを使ったほうがいい気がする.
import sys
import subprocess
import xml.etree.ElementTree as ET
filename = sys.argv[1]
cmd = '/usr/bin/pdftotext -bbox-layout -f 1 -l 1 {0} -'.format(filename).split()
result = subprocess.run(cmd, stdout=subprocess.PIPE).stdout.decode('utf-8')
tree = ET.fromstring(result)
page = tree[1][0][0]
first_block = page[0][0]
titles = []
for line in first_block:
words = []
for word in line:
words.append(word.text)
titles.append(' '.join(words))
title = ''.join(titles)
print(title)
結果
https://sugarheart.utgw.net/static/pdf/ にあるPDFだと1つを除いてうまくタイトルを取得することができた.
Googleスライドのテーマを使ったものについてもうまくいった.
うまくいかなかったのは次のスライド.
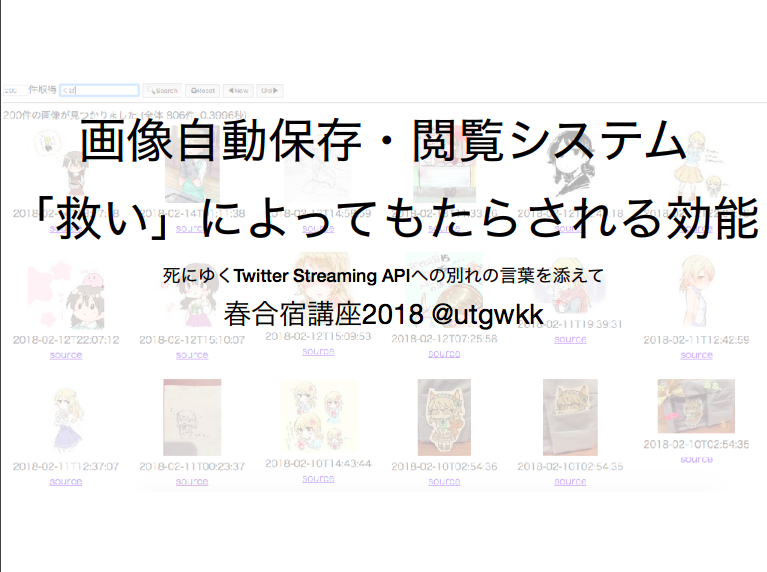 gyazo.com
gyazo.com
これを pdftotext にかけると,複数の <flow> が出てくる.
 gyazo.com
gyazo.com
この場合は最初の<flow> がタイトルだろうという判断がすぐできるのでスクリプトを改変して対応した.
自分のスライドのテーマやレイアウトの傾向をだいたい決めておけば,それに対応するスクリプトをすぐに用意できそう.
今後の課題
- いろいろな種類のスライドに対応してると便利??
- じぶん用だとあまり困ってない
- 大量のif文で捌く???
pdftotext のPythonバインディングないのかな




